
Rare Not Random
Using Token Efficiency for Secrets Scanning

In Regex is (almost) All You Need we learned that using a combination of regular expression patterns, entropy, and rule-based filters are an effective way to detect candidate secrets. Regex is used for casting a wide net to identify candidates. Entropy is used as a primary filter on the captured candidates and additional filters like presence of commonly used english words, or filtering on known “safe” files like go.sum are applied last. Entropy does a decent job at filtering false positives but leaves a lot to be desired, especially when evaluating generic secrets. Could there be something better than entropy for that primary post-regex-capture filter? This post examines whether Byte-Pair Encoding can serve as a more effective alternative to entropy for secrets scanning.

I want to thank GitHub user “DmitriyAlergant” for submitting this idea in an issue on the Gitleaks repo.
Entropy
What the heck is entropy? According to John von Neumann when talking with Claude Shannon, “no one really knows”, but Wikipedia does. Shannon Entropy measures the average unpredictability of a string aka how much information each character carries. When characters are uniformly distributed (many distinct characters, no clear pattern), each one is harder to predict, so entropy is high. When a few characters dominate, the next character is easy to guess, so entropy is low. In practice that means something like aaaaaa111111 scores low, while something like xA9fP2qL0sRw scores high. With regards to secrets detection, this makes entropy a decent first pass at spotting "random looking" strings (candidate secrets).
But do we really want randomness to be our primary filter for secrets detection? Excuse the “it’s not X, it’s Y” LLM trope here - but secrets aren’t just random, they’re statistically unusual compared to the natural distribution of human-written text. Put more plainly, secrets are rare. A b64 encoded string, a UUID, an actual secret, and a weird-looking dependency string can have similar entropy scores despite being fundamentally different in how often they appear in the real world. Entropy can’t tell the difference between “this looks random” and “this almost never shows up in English text or source code.” Instead of measuring randomness with entropy, what if we tried to measure how out-of-vocabulary or how non-natural-language a string is.
Byte-Pair Encoding
Okay so how do we detect how non-natural-language looking or rare a string is? Byte-Pair Encoding (BPE) of course! Byte-Pair Encoding tokenization implicitly reflects the frequency distribution of the text it was trained on. Common words and subwords get merged into long tokens, while rare or unnatural strings get broken into many short tokens.
Here’s a couple examples using the cl100k_base tokenizer1:
“Hello World” → [15339, 1917]
“lookingatcomputer” → [20986, 266, 44211]
“kj2h3f2fuaafewa” → [93797, 17, 71, 18, 69, 17, 69, 4381, 2642, 365, 64]
Because BPE builds its vocabulary by repeatedly merging the most common character pairs in the training data, its tokenization naturally reflects how frequently different patterns appear. Kinda sounds like that rarity thing we’re trying to measure doesn’t it?
Common English words get their own individual tokens because they appear frequently in training, e.g., “password” is token [3918]. “github” is token [5316]. “function” is token [1723]. But a random API key like `ghp_xK7mP9qL2wR5nT3vJ8fY`?

The tokenizer has likely never seen that specific sequence during training so it breaks the string into smaller pairs eventually falling back to individual bytes which end up tokenizing to [876, 79, 3292, 42, 22, 76, 47, 24, 80, 43, 17, 86, 49, 20, 77, 51, 18, 85, 41, 23, 69, 56]. That's 22 tokens for a 24 character string which means the tokenizer barely recognized anything in it.
Check out https://tiktokenizer.vercel.app/?model=cl100k_base to see how different strings get tokenized.
Token Efficiency
If BPE tokenizers break rare strings into many short tokens, then we can measure how rare a string is by comparing the original string length to the number of tokens produced. Heck, let’s call it Token Efficiency.token_efficiency = len(string) / len(tokens)
Natural language maps well to the tokenizer's vocabulary, so common phrases produce fewer tokens. Secret-like strings don't, so they produce many tokens.
Consider our example of ghp_xK7mP9qL2wR5nT3vJ8fY. It has a token efficiency of 1.1 (a 24 character string producing 22 tokens). A phrase like Hello World has an efficiency of 3.7 (11 characters split into 3 tokens). If secrets consistently produce lower token efficiency scores and everyday text produces higher ones, then token efficiency could be a useful post-regex filter for secrets detection.
To test this idea, we can turn to the CredData dataset, which contains thousands of labeled examples of true secrets and non-secrets extracted from real-world repositories. If token efficiency actually tracks rarity or “non-everyday-language-ness,” then looking at the distribution of token efficiency on the CredData datasets’s secret values might reveal a gap between secrets and non-secrets.
CredData
The CredData dataset is split into index files and data files. The index files store the metadata you need, such as labels, line and column ranges, and filenames. They do not contain the actual secret values, so you have to reconstruct each secret by slicing the source files at the specified ranges. That is the approach I took. I extracted every labeled secret value directly from the dataset. This means we are not evaluating whether token efficiency can detect secrets on its own. Instead, we are evaluating whether token efficiency can classify already captured candidate secrets, which makes it a post-regex filtering step rather than a standalone detector.
You can take a look at the code that produces these charts here:
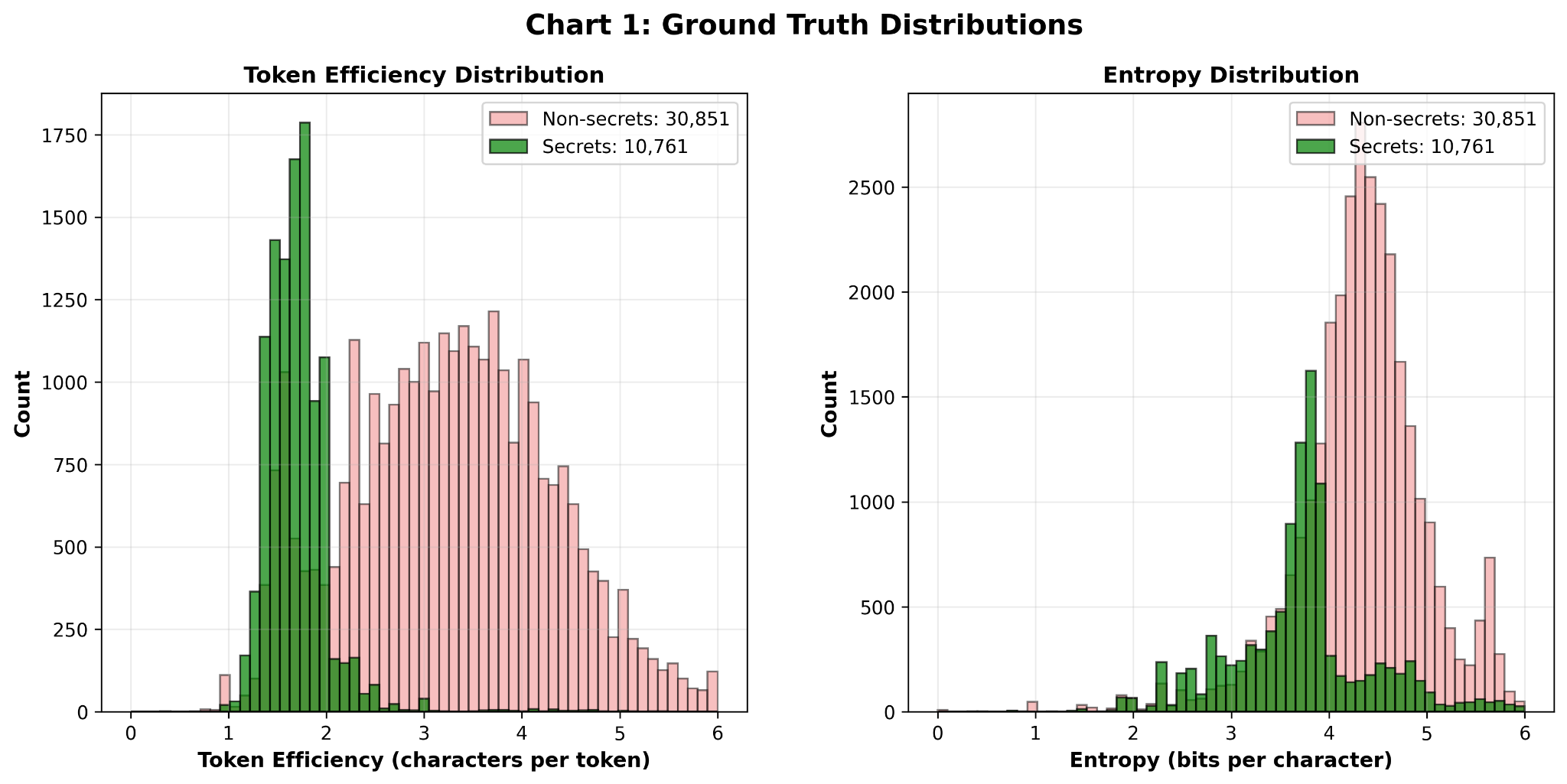
That looks promising! It looks like 2.5 is a good minimum cutoff for Token Efficiency. Gitleaks uses an entropy cutoff of 3.5 for generic secrets.
Using those cutoffs let’s take a look at the classifications.
Token Efficiency: Precision=57.3% Recall=98.6% F1=0.725
Entropy: Precision=21.1% Recall=70.4% F1=0.325A recall of 98.6% is pretty dang good. We’re correctly classifying almost all true secrets while only leaving 149 false negatives on the table. There are a decent amount of false positives for Token Efficiency, but the difference between this and entropy is night and day. Entropy generates 28k FPs (nearly 4x more than Token Efficiency) and 3k FNs. Throwing a simple word filter into the mix helps both methods, but token efficiency still wins on F1 score. The word filter ignores secrets with more than one occurrence of a 4 or more character word.
TE + Word Filter: Precision=80.4% Recall=95.8% F1=0.874
Entropy + Words Filter: Precision=76.6% Recall=67.1% F1=0.715This filter does a lot of the heavy lifting for entropy specifically but also helps us out with filtering FPs for token efficiency too. For token efficiency we went from 7894 FPs → 2508 FPs while only introducing 308 new FNs when applying this word filter which helps us significantly with that F1 score.
If you want to try to reproduce these results you can check out some of the code here https://github.com/zricethezav/creddata_helpers.
Examples
Let’s take a look at some secrets that entropy misses but token efficiency catches.
e2aa9ae57d893a1
This guy has an entropy of 3.125. Pretty high but not quite 3.5 which is what Gitleaks and some other secret detectors use as a cutoff. e2aa9ae57d893a1 produces [68, 17, 5418, 24, 6043, 3226, 67, 26088, 64, 717] for it’s cl100k_base tokens which yields a token efficiency of 1.6, well below the token efficiency cut off of 2.5.
mcjrx4
Here we have a password and not a very good one at that. Passwords are a tough category for the entropy filter because they're often (and unfortunately) short and short strings typically have low entropy values. This one has an entropy of just 2.58. But the tokenizer breaks it down to near byte-level tokens [13183, 73, 12940, 19], giving it a token efficiency of 1.5. Six characters, four tokens. The tokenizer doesn't recognize it as natural language and that's exactly the signal we want.
U@kkf8fo!!
Another password. This one is interesting because of the special characters. One of the challenges in secrets detection specifically for generic secrets and passwords is crafting a regex that captures most secrets. The problem with using a regex that aims to capture most secrets is that it has the potential to let a lot of false positives through, like emails, urls, etc. So for every special character like @ or ! or / you define in your capture group’s character class you are increasing the chances of letting in more false positives. Because of this we can see that Gitleaks’ generic capture group is pretty strict: [\w.=-]{10,150}. With a token efficiency filter we could potentially loosen up that pattern to include more special characters. Okay so with that context here is how entropy and token efficiency compare for this example. U@kkf8fo!! has and entropy of 2.72 and produces these tokens [52, 31, 19747, 69, 23, 831, 51447] with a token efficiency of 1.42 (10 characters, 7 tokens).
A quick note on passwords. Token Efficiency does not do well with classifying bad passwords like “password123” or “chibearsfan123”. These passwords are basically natural language which means a high token efficiency value. Pass phrases also don’t do well because those are usually just straight up words.
Performance
The impact on performance is negligible. Average time per string to calculate entropy on the captured CredData secrets is 4.55 µs vs 11.75 µs to calculate token efficiency2 (using cl100k_base). A 2.5x difference may seem like a lot but you gotta remember when it comes to secrets detection the bottleneck is the regular expressions, not the quick filters like entropy or token efficiency that come after.
Token Efficiency w/ Betterleaks
The maintainers of the CredData dataset created an impressive secret scanner called CredSweeper which uses regex, entropy and RNNs to detect secrets. In a world filled with “LLMs can detect secrets with ZERO false positives” (both in academia and in industry3), it’s refreshing to see the engineers at Samsung building out a secrets detector based on more “traditional Machine Learning”. Props. CredSweeper boasts an impressive .85 F1 score when tested against CredData. That’s pretty good! Let’s see if we can beat it with the new Token Efficiency filter in Betterleaks.
Oh right. What is Betterleaks? It’s a new project that builds on the legacy of Gitleaks. I’ll talk more about that in another post but all you need to know is it’s a drop-in replacement for Gitleaks that I’m maintaining.. and it’s gonna be better… because of the name.
This config adds a couple new rules and tweaks some small things in the existing default config. Using this config and running Betterleaks against the CredData dataset yields an F1 score of .892.
(Token Efficiency + (Low) Entropy on Generic Rule + Rule tweaks) Benchmark Results:
========================================
TP (True Positives): 10796
FP (False Positives): 1031
TN (True Negatives): 42572
FN (False Negatives): 1578
----------------------------------------
Accuracy: 0.9534
Precision: 0.9128
Recall: 0.8725
F1 Score: 0.8922Pretty good.

Using just Token Efficiency gives us:
(Just Token Efficiency + Rule tweaks) Benchmark Results:
========================================
TP (True Positives): 10843
FP (False Positives): 1722
TN (True Negatives): 41881
FN (False Negatives): 1531
----------------------------------------
Accuracy: 0.9419
Precision: 0.8630
Recall: 0.8763
F1 Score: 0.8696Without using a low entropy cutoff on the generic rule when using the Token Efficiency filter we introduce ~700 FPs. Still, without that entropy filter on the generic rule we get an F1 of .86 which isn’t bad.
How do we score without the Token Efficiency filter but instead rely on rule tweaks and entropy only?
(Just Entropy + Rule tweaks) Benchmark Results:
========================================
TP (True Positives): 8498
FP (False Positives): 1041
TN (True Negatives): 42562
FN (False Negatives): 3876
----------------------------------------
Accuracy: 0.9122
Precision: 0.8909
Recall: 0.6868
F1 Score: 0.7756Alright so .892 vs .776 is a pretty big difference. Using just the entropy filter adds more than 2000 FNs and 80 FPs vs the Token Efficiency filter.
You can see the code for the Token Efficiency filter here.
func (d *Detector) failsTokenEfficiencyFilter(secret string) bool {
analyzed := secret
if len(analyzed) < 20 && strings.ContainsAny(analyzed, "\n\r") {
analyzed = newlineReplacer.Replace(analyzed)
}
tokens := d.tokenizer.Encode(analyzed, nil, nil)
matches := words.HasMatchInList(analyzed, 5)
if len(matches) > 0 {
return true
}
threshold := 2.5
if len(analyzed) < 12 {
threshold = 2.1
matches := words.HasMatchInList(analyzed, 3)
if len(matches) == 0 {
threshold = 2.5
}
}
return float64(len(analyzed))/float64(len(tokens)) >= threshold
}The filter is slightly adapted compared to the one used in the chart comparison. This is to take into account for short passwords and secrets with newlines in them (we strip newlines before running the Token Efficiency analysis on the candidate).
Couple of other notes:
I couldn’t get the benchmarking script supplied by CredData working so I (claude) created my own. Sorry if this is bad science but hey you can check my (claude) work since it’s open source.
Duplicates were removed from the CredData dataset.
All the new rules and tweaks to existing rules weren’t “secret specific”. I.e., I tried not to game the benchmark.
Some secrets labeled as FPs in the CredData dataset seem erroneously labeled so honestly the F1 couple be +/ .05 maybe.
Thanks for reading. And big shout out to the maintainers of CredData/CredSweeper and Dmitriy Alergant for getting me started down this rabbit hole.
for all the examples we look at we’ll be using the cl100k_base tokenizer.
Timing taken from the chart generator script which calculates entropy and token efficiency for each candidate secret.
shots fired! I repeat shots fired! I’m sorry but it’s not impressive when you ask an LLM to detect secrets if that’s your secret sauce. For 3 reasons - 1. it’s lazy. 2. it’s expensive. 3. it’s slow. LLMs for post-detection analysis is mad chill tho. I’m not an LLM hater, this is just a particular hill for me.
Super rad. Intuitively I would not have expected a meaningful difference between token efficiency and entropy.
I wonder if other tokenizers would be more or less accurate for calculating token efficiency. Youd probably have to adjust cutoff to 'calibrate' different tokenizers but itd be interesting if accuracy could be pushed even higher.
hey great writeup!
just because its also written in the post:
"A quick note on passwords. Token Efficiency does not do well with classifying bad passwords like “password123” or “chibearsfan123”. These passwords are basically natural language which means a high token efficiency value. Pass phrases also don’t do well because those are usually just straight up words."
What do you think is the best way to find these than? or its something to drop in a secret scanner because "who uses such a weak password should be pwned anyway"?