
Regex is (almost) all you need
How Gitleaks combines regex, entropy, and allowlists to find secrets

When it comes to secret detection, regex is all you need. Almost. A well crafted regular expression can filter out lots of false positives while capturing things that look like secrets1. Using regular expressions for secret detection does have its limitations. For example, it would be difficult to craft a regular expression that could correctly label MyServiceToken=”secret123” as a false positive and MyServiceToken=”8dyfuiRyq=vVc3RRr_edRk-fK__JItpZ” as a true positive.
In order to differentiate between “clearly not a secret” and “looks like a secret” we have to introduce some filtering using allowlists and entropy, but before we get to covering those filters, let’s first take a look at how we capture things that look like secrets using regular expressions. In this post we’ll examine the generic rule in Gitleaks as it provides the widest funnel for capturing things that look like secrets.
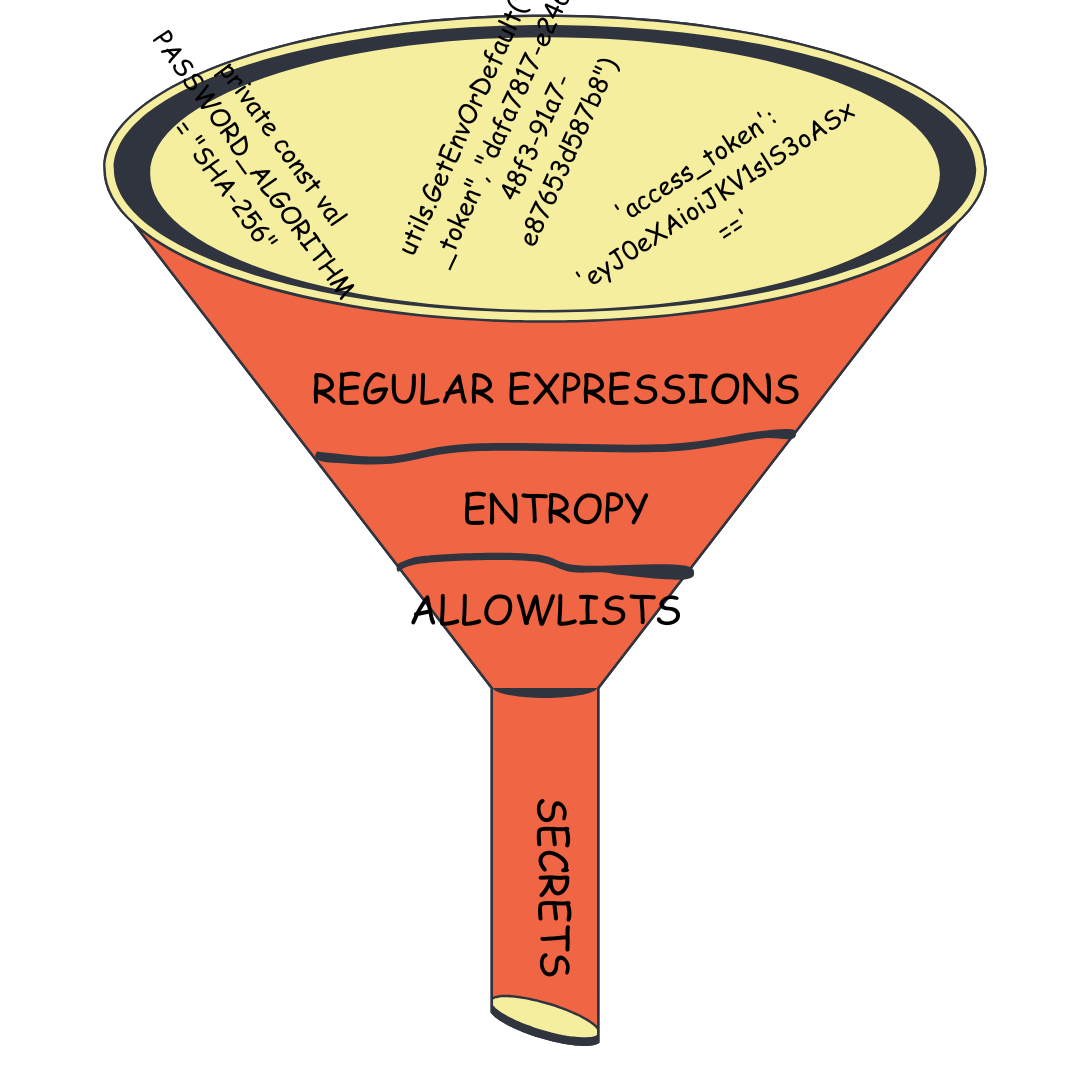
The Generic Rule
I don’t have any data on this but if I were to guess, most Gitleaks users use the default configuration which includes a generic rule. Below is the regular expression for the generic rule.
(?i)[\w.-]{0,50}?(?:access|auth|(?-i:[Aa]pi|API)|credential|creds|key|passw(?:or)?d|secret|token)(?:[ \t\w.-]{0,20})[\s'"]{0,3}(?:=|>|:{1,3}=|\|\||:|=>|\?=|,)[\x60'"\s=]{0,5}([\w.=-]{10,150}|[a-z0-9][a-z0-9+/]{11,}={0,3})(?:[\x60'"\s;]|\\[nr]|$)
This regular expression is the result of an active community of Gitleaks users regularly submitting PRs and opening issues. Special thanks and recognition go to Richard Gomez, whose ongoing contributions to Gitleaks have been invaluable, particularly his work on the generic rule. You can see how this rule is constructed and tested here.
Before diving into the generic rule’s regex, let’s cover some regex 101 as it relates to secret scanning:
Metacharacters are characters that have special meaning during pattern processing. You can think of metacharacters as the underlying grammar for regular expressions. The core metacharacters include:
.(matching any character),^and$(anchoring to line start/end),*,+, and?(quantifiers),[](character classes),\(escaping),|(alternative), and()(grouping).Character classes, or character sets, are denoted by square brackets and are used for matching one character out of the class, or set. In the classic example
gr[ae]y, matches “gray” and “grey”. Hyphens can be used to specify ranges like[a-d]which is equivalent to[abcd]. You can also combine shorthand character classes like\wwithin character classes like[\w.=]which is equivalent to[a-zA-Z0-9_.=].Alternatives (also referred to as alternations) within subexpressions (also referred to as groups) are useful for telling the engine to look for this string or that string. For example, if I wanted to find all occurrences of “prefix” and “suffix” I could use this regex:
(pre|suf)fix. Alternatives are denoted by the pipe character,|and subexpressions are denoted with open and close parens,( ). When reading and writing regular expressions you can think of alternatives as the logical OR operatorCapture groups are a kind of subexpression that can be used to extract targeted information from a regular expression match. For example if we wanted to capture the content of all the <h1> tags in an html document we could use this regex
<h1>(.*?)</h1>. The pattern.*?tells the engine to match any character zero or more times as little as possible using the lazy modifier,*?.
So if we are parsing some html doc that looks like:
<h1>hello world</h1>...
content
...
<h1>goodbye</h1>
then we could extract “hello world”, and “goodbye” using capture groups. Capture groups are particularly useful in secret detection as we can specify which part of a match contains the secret.
Non-capture groups are another kind of subexpression that are useful when we don’t want to capture the contents of a subexpression, but we do want to use alternatives. Non-capture groups are initiated by
(?:and closed with). The generic secret pattern makes heavy use of non-capture groups as there are many cases where we want to use alternatives like matching potential identifiers/keywords (access, token, password, key, etc) and assignment/association operators ( :=, =, :, etc).
There are different “flavors” or engines of regular expressions. Gitleaks uses re2. Different flavors have different features. A good comparison of features between flavors can be found here.
https://www.regular-expressions.info and
https://regex101.com are great resources.
Ok, now let’s dive into different sections of the generic rule’s pattern. To start each section we’ll read the pattern in plain English then explore how it relates to secret detection. The generic rule’s pattern starts with (?i) which is a “mode modifier” telling the regex engine to ignore case. There are lots of other modes you can toggle but we are only concerned about case insensitivity.
Prefix
[\w.-]{0,50}?
Match between 0 and 50 occurrences of either a word character, dot, or hyphen, matching as few times as possible.
By itself this isn’t a very useful pattern. It is useful when paired with more restrictive patterns, like the keywords pattern in the next section. The purpose of the prefix pattern is to match identifier/keyword prefixes or names. For example, if I have a variable defined as MyServiceToken = “mytoken123” we want MyService to be included in the complete match.
Keywords
(?:access|auth|(?-i:[Aa]pi|API)|credential|creds|key|passwd|password|secret|token)
Match any of these words, where most words can be in any case except 'api' which must be specifically ‘api’, ‘Api’, or ‘API’.
Secrets don’t exist in a vacuum and to borrow a quote from Kamala Harris, secrets “exist in the context of all in which they live and what came before them”. There is usually some context, like the string “token” or “secret”, associated with a secret. To find this context we rely on keywords. Keywords are common words that could indicate there is a secret nearby. In the previous section we used the example MyServiceToken=”mysecret123”. The secret is mysecret123 but the keyword that lets us know there might be a secret nearby is Token. Combining the prefix pattern with the keyword pattern yields the match, MyServiceToken. The full string, MyServiceToken, is referred to as an identifier.
You may be wondering what’s up with that “api” group? We turn on case sensitivity, ?-i:, for that group because a case-insensitive “api” string could show up in camel cased compound words like “snapIntoView”, “ultraPicture”, “gapInBetween”, etc.
Optional Identifier Suffix
(?:[ \t\w.-]{0,20})
Match between 0 and 20 characters that can each be either a space, tab, letter, number, underscore, dot, or hyphen.
After the identifier there may be spaces, tabs, dots, hyphens, etc. This group ensures our regex does not break if optional characters are encountered. Imagine the example “MyServiceTokenProd=`mysecret`. The previous sections’ patterns would only capture part of the identifier, MyServiceToken. This pattern matches remaining characters that could be part of the identifier but before the assignment/association operator. So in the example above, the full identifier would be matched, MyServiceTokenProd.
Quote/Space Separator (Optional)
[\s'"]{0,3}
Match between 0 and 3 characters that can either be any whitespace character, single quote, or double quote.
This pattern matches spaces and quotes after the identifier. We want to include quotes so that common key-value syntax is supported (think json, Golang maps, python dicts, etc). For example, in the string "key" : "value", the identifier, key, is matched by the prefix and keyword patterns, while this pattern matches the following double quote and space, “\x202.
Assignment/Association Operator
(?:=|>|:{1,3}=|\|\||:|\?=|,)
Match any of the alternatives.
Secrets in code usually come in some form of {identifier} {operator} {secret}. This pattern attempts to capture the operator which is an important feature to look for when scanning data for secrets as most secrets leaked in code are assigned string literals. Common operators include: “=” for standard assignment in lots of programming languages, “:=” Go style assignment, “:” simple key-value separator, etc.
Quote/Space Separator (Optional, again)
[\x60'"\s=]{0,5}
Match between 0 and 5 characters that can either be a backtick, single quote, double quote, or any whitespace character.
This pattern is similar to the previous quote/space separator pattern but includes a backtick in the character class. The character class range is increased to 5 to support triple quotes/backticks string literals, e.g., key = ```definitelyNotASecret```. In this example the space character after the equals sign and first set of triple backticks gets matched.
Token Capture
([\w.=-]{10,150}|[a-z0-9][a-z0-9+/]{11,}={0,3})
This regex captures 10 to 150 characters that can either be alphanumeric, underscores, periods, equal signs, and hyphens, or it matches a Base64-encoded string that begins with an alphanumeric character, followed by at least 11 Base64 characters (letters, numbers, plus signs, or forward slashes), and optionally ends with up to three equal signs for padding.
Let’s actually capture the damn thing3. This capture group contains two alternatives: one for matching generic tokens and secrets, and another for matching base64-encoded secrets. The character class[\w.=-] covers common characters found in API tokens and secrets. While we could expand this character class, doing so would increase false positives like myServiceToken = os.GetEnv("MyServiceToken").
Ending
(?:[\x60'";\s]|\\[nr]|$)
Match a backtick, quote, double quote, any whitespace character, or semi-colon OR an escaped newline/carriage return OR the end of the line.
You may be wondering why we don’t use word boundaries here. We don’t use \b because \b only works when it is adjacent to \w which means we may be prematurely exiting our capture from the previous section’s pattern. To demonstrate this, image we have this variable, myServiceToken = "definitelySecret123===". If we use \b we only capture definitelySecret123, ignoring the three equal signs which are part of the secret.
Putting it all together we get this regular expression:
(?i)[\w.-]{0,50}?(?:access|auth|(?-i:[Aa]pi|API)|credential|creds|key|passw(?:or)?d|secret|token)(?:[ \t\w.-]{0,20})[\s'"]{0,3}(?:=|>|:{1,3}=|\|\||:|=>|\?=|,)[\x60'"\s=]{0,5}([\w.=-]{10,150}|[a-z0-9][a-z0-9+/]{11,}={0,3})(?:[\x60'"\s;]|\\[nr]|$)
It does a pretty good job capturing things that look like secrets and ignoring things that don’t. However, false positives still get matched like tokenName := "Prod1MyService". In order to filter out false positives like this we need employ additional filtering tools like entropy and allowlists.
Entropy
In information theory, entropy measures the average unpredictability of characters in a string, expressed in bits per character. The formula to calculate entropy is straightforward: for each unique character, multiply its probability by its surprisal4, then sum this product across all characters.
To demonstrate, let’s calculate bits per character for the string “hello”. The probabilities of each character are:
“h” = ⅕ = 0.2
“e” =⅕ = 0.2
“l” = ⅖ = 0.4
“o” = ⅕ = 0.2
Using these values we get the expression:
The result is 1.922 bits per character, which is relatively low when compared to things that look like secrets.
Entropy by itself isn't a very good heuristic for determining whether something is a secret or not. Consider this line of Go code: if err := readUntilSafeBoundary(reader, n, maxPeekSize, peekBuf); err != nil. Despite not containing anything that looks like a secret, this line has an entropy of 4.24 bits per character which is pretty high. Clearly using just entropy doesn’t cut it, but if we combine entropy and regular expressions we get better results.
So what’s a good value for the entropy threshold? First we should ask the questions, what are the theoretical maximum and minimum entropies? The theoretical maximum entropy for a secret captured by the generic rule’s regular expression is 5.83. This maximum entropy requires a string of 150 characters where each character appears exactly once. The theoretical minimum entropy is 0, which happens when a string of any length consists of only one repeated character, e.g., “aaaa”. After some trial and error and feedback from the Gitleaks community we landed on 3.5.
To demonstrate how the entropy threshold filters out false positives, let’s look at two string assignments: myServiceToken = “extremelySecret123” and myServiceToken = “8dyfuiRyq=vVc3RRr_edRk-fK__JItpZ”. Both of these string values are captured by the generic rule’s regular expression we described above, but only one meets the entropy threshold. 8dyfuiRyq=vVc3RRr_edRk-fK__JItpZ has an entropy of 4.11, high enough to be considered a secret, whereas extremelySecret123 has an entropy of 3.3, low enough to be filtered out.
Allowlists
Allowlists are a set of conditions that tell Gitleaks to ignore, or “allow”, certain matches even if they look like secrets and pass the entropy threshold. Each allowlist entry can include one or more of the following checks:
Commits: Does the secret exist in a commit that is allowed? This check is only applicable if you are scanning a git repo.
Paths: Does the secret exist in a file path that matches one of the paths in a list of paths expressed as regex? You can easily exclude file types here as well, e.g.,
(?i)\.(bmp|gif|jpe?g|svg|tiff?)$.Regexes: Does the target (captured secret, match, or entire line) match any of the regexes in a list of allowed regex patterns?
StopWords: Does the secret contain any of these plain-text words?
The default allowlist behavior ignores the secret if any of the conditions are met. You can change the requirement of an allowlist entry by setting MatchCondition to AND which requires all of the conditions in an allowlist to be met.
Gitleaks provides a comprehensive allowlist at the global level by default. The global allowlist filters out vendor directories, lockfiles, and media file extensions. It also provides a list of 10 regex patterns like ^${([A-Z_]+|[a-z_]+)}$ which filter out variable expansions in Bash.
The generic rule has two allowlist entries. The first entry ensures that the captured secret has at least one character outside this character class ^[a-zA-Z_.-]+$. It’s a somewhat hacky way of enforcing that generic secrets need at least one digit or special character. The second entry contains a list of patterns and stopwords. Here are a few example allowlist patterns targeting a match:
api[_.-]?(?:id|name|version) this pattern ignores variables like api_name=”my_cool_api_123”
(?:bucket|foreign|hot|idx|natural|primary|pub(lic)?|schema|sequence)[_.-]? this pattern ignores obvious non-secret variables like foreign_key=”userID”.
The second allowlist entry also contains a list of stopwords. If a secret contains a stopword, then it gets ignored. The list is 1479 words long and contains common words used in programming; cache, admin, build, www, etc. Each word must be at least 4 characters long. Remember these two allowlists are specifically for the generic rule which is part of the default Gitleaks config. If you don’t agree with how strict or relaxed the allowlist is you can always supply your own config, or override the existing default.
End
Okay, so you might need a little more than regular expressions. While the generic rule's regex effectively casts a wide net to capture potential secrets, it needs additional filtering mechanisms to be truly effective. By combining regex with entropy filtering and sane allowlists, we can better distinguish between things that look like secrets and things that don’t.
If you want to be sure a secret is a live secret you can use TruffleHog, which verifies secrets. TruffleHog does not have a generic secret detector by default as it would be impossible to verify a generic secret in a reasonable timeframe.
The hex sequence, \x20, represents a space character.
Secret.